
Real-time data insight and foresight with analytics: a case study for a large cellular network provider
FOREWORD

Does a cellular network company need a real-time data solution?
The short answer: we think yes!
The long answer: we have prepared a dedicated post to answer this question based on our recent experience building an analytics system for an Asian cellular network provider.
Without further intro, let’s get into the “why” question.
Why Invest in Real-Time Data Analytics System?
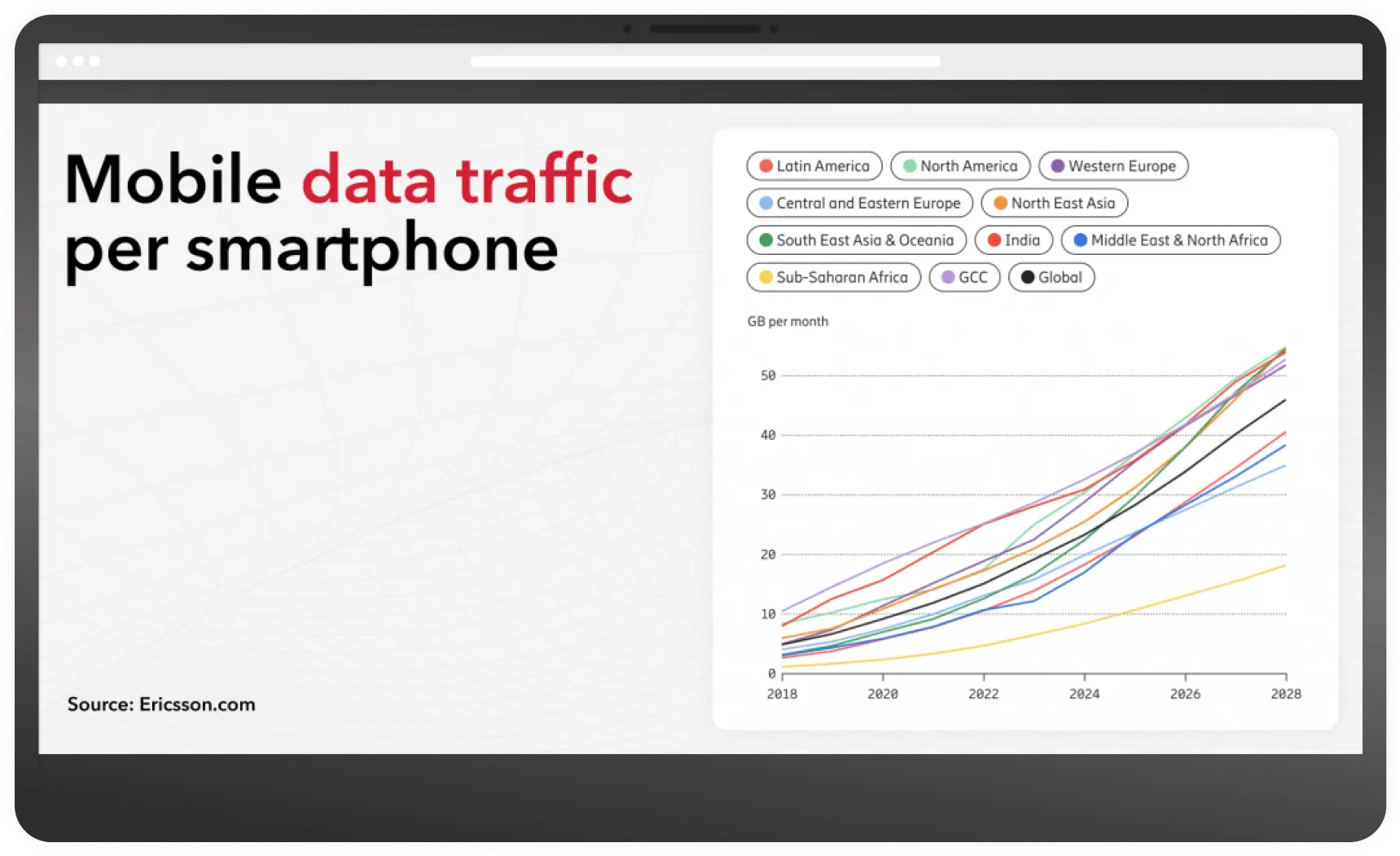
Cellular network providers generate and carry breams of user data: GEO location, device type, phone number, app usage, and many other forms of intelligence. Everything flows through mobile network providers. The amount of traffic is growing exponentially every year and for every country (see graph above).
If you manage to harness this data — from targeted advertising to security monitoring and traffic engineering - you can improve your business operations on so many levels.
How Businesses can Use Real-Time Data Analytics





How development started: Admixer + Mobile Carrier
The large mobile network carrier struggled to build an analytics system to aggregate, process, and analyze their customer data.
With a growing amount of internet traffic passing through the client’s mobile network, there was an opportunity gap they had no intention of missing.
Someone had to implement a robust analytics system — not just to store massive data but leverage it for timely decision-making.
They hired Admixer.
major factors contributing to the project’s complexity

Cell providers handle a massive amount of internet traffic, which can be challenging to capture, store, and analyze effectively. The sheer volume of data requires robust infrastructure and analytics capabilities to process and derive meaningful insights from the traffic data.

Analyzing internet traffic in real time is crucial for detecting and responding to network issues promptly. However, the high-speed nature of network traffic makes real-time analysis complex and demanding. Cell providers need sophisticated tools and algorithms that can handle the continuous flow of data and provide insights in near real-time.

Cell networks are complex, consisting of multiple technologies, protocols, and network elements. Analyzing traffic across different network segments and technologies, such as 2G, 3G, 4G, and 5G, adds complexity to traffic analysis. Cell providers must account for this complexity and ensure compatibility with various network components and protocols.

Implementing a system for analyzing internet traffic can involve significant costs for cell providers. From custom development––to implementation and ongoing maintenance, the project takes a solid paycheck to cover all operations. But to give you an idea, you think of costs as the two major factors:
1. Hardware costsAnalyzing large volumes of internet traffic requires robust infrastructure, including high-performance servers, storage systems, and network infrastructure.
2. Software costsCell providers may need to acquire or develop sophisticated analytics software to process and analyze internet traffic data effectively. This includes investing in software licenses, development resources, and ongoing support & maintenance costs.
Laying the Groundwork for the Data Puzzle
Creating such a complex analytics system is no easy task. Before getting started with this big huge project, you need an architectural framework for applying the big data analytics system in the mobile carrier’s business.
Because it’s not just big data - it’s GIGANTIC data.
Even if the solution for the data collection is found, storing such an enormous amount of data is not even a hard task, it’s almost ridiculous. And let alone storing this data, how do you analyze it? And in real-time?
Here at Admixer, we follow a 4-step framework to parse, collect, store, and analyze this amount of data landing in a clear project’s roadmap. For all four steps, we need to cover the high availability (HA) requirements, which will multiplicate the amount of storage twice. The parsing of the data should cover HA as well, as another component of the system.


- Creating reports for phone numbers
- Creating the location activities reports
- Creating the application usage reports
-
Creating the bonded report:
-
Which phone number/s uses a defined application
- in a defined location
- in a defined time window.
-
Which device/s uses a defined application
- in a defined location
- in a defined time window.
-
Which phone number/s uses a defined application
How Did We Achieve the Goals and Covered the Requirements for the Large Cellular Network Carrier?
Data generation is outside of Data Center. In other words, Data Sources are remotely accessible over the network. Any remote connection should be designed as Highly Available. And that means that the connection should be duplicated.
But even more so: if the Data Center is unavailable from the remote location perspective, the data should not be lost. To avoid data loss because of the connection between the remote location and the central data center, we have created the opportunity to write data locally till the connection is recovered.
For each remote location, the data should be buffered if Data Center is not available, which led us to create a special proxy service.
The proxy service has been created, which is deployed directly at the Data Sources.
This proxy service pulls data from the Data Sources and pushes it to the Data Center. The proxy service has a multi-endpoint connection configuration that puts the data only to live endpoints. It provides us the opportunity to design a High Available Data Collection layer (protocol parsers).
If all Data Collection layer endpoints are not available, the Proxy service starts to write the data locally on storage till the Data Processing layer is available.
After recovery of the availability of the Data Collection layer, the service resumes the pushing of the data to it and pulls the data both: from the Data Sources and from the local storage.
High-Level Architecture Diagram
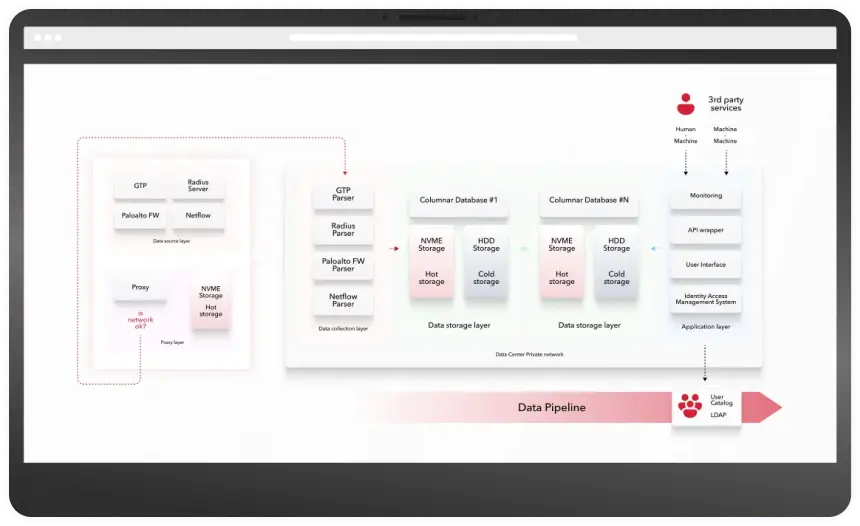
Data Collection layer





why did we use rust?
The Rust programming language was used to avoid high-memory usage and avoid the garbage collector. With Rust language, we have created very powerful parsers that can handle such an amount of traffic on reasonable hardware.
Rust provides high-level abstractions, such as iterators and closures, without sacrificing performance. The language’s ownership model and borrow checker allow for efficient memory management and eliminate many runtime overheads associated with garbage collection. Rust has built-in support for safe and efficient concurrency through its ownership and borrowing system. It provides abstractions like threads and asynchronous programming (using async/await), allowing developers to write highly performant concurrent code without sacrificing safety.
Data Storing layer
The cluster of Columnar Database has been deployed by dividing the Hot storage (NVME SSD) and Cold storage (HDD). Hot storage is a limited set of dimensions and metrics that the client defines as those that need the fastest possible access. Such storage is capable of preparing data in milliseconds or seconds for all time. This is achieved through the correct preparation of the data structure, as well as reduced data sets, on which the search will be carried out and focusing only on the necessary ones.
Cold storage, in turn, is capable of storing huge amounts of data but at a much slower rate of data issuance. All dimensions and metrics are stored in the cold storage for the entire time, which allows, although not quickly (we are talking about minutes and tens of minutes), to get any necessary data.
Such a separation allows for better distribution of read operations to fast NVME disks and store functionality to HDD disks.
How Did We Go About the Data Processing Flow?
Storing information in your database is like sorting books in a library. The data should be easily accessible to improve the performance of SQL requests.
The mechanism of Materialized Views on Columnar Database provides opportunities to prepare data on the fly and quickly process only necessary data without the need to scan the whole amount of data and find the needed values.
All data is configured initially into a table with the Buffer engine, which is used to buffer data in order to avoid frequent inserts in the Columnar Database (the maximum recommended number of inserts in the Columnar Database is 1000 per second per server). For each protocol, we allocate a separate buffer.
“Think of your database as a book library. People stroll down the aisles and scan shelves to pick out the one book that piques their interest. When you search for a book in alphabetical order, it might take you a while to find it.
However, once you look for books by your favorite genre, the odds are that you find your preferred book much faster.”
Oleksii Koshlatyi, CTO
After buffering, the data is sent to the table with the Null engine. This type of engine is used in cases where we do not need to store the incoming set of events in one place. And on this table, you can set up proofreading using MaterializedViews to other tables in which real data will be stored. MaterializedView is like a trigger for data insertion. After the data enters the table on which the MaterializedView is configured, the data is converted using an SQL query into the necessary ones and inserted into the table where this data will be stored.
The MergeTree engine was chosen to store data in a flat form. This allows you to store data without aggregating it in its original state. MergeTree is the main engine in the Columnar Database and provides a lot of options for working and storing data.
For more efficient data retrieval, it is better not to use large flat tables with many dimensions. For these purposes, it is better to create smaller aggregations with the minimum required set of dimensions and use them for queries. A similar scheme is also built based on MaterializedView and writing data to a specific table.
For such tables, it is desirable to use aggregations, which will allow more efficient storage and processing of data. The Columnar Database uses one of the engines of the MergeTree family — SummingMergeTree — for such purposes.
To get the data fast and quick, it is best to send queries to pre-aggregated tables.
Data Processing Flow via Pre-Aggregated Tables
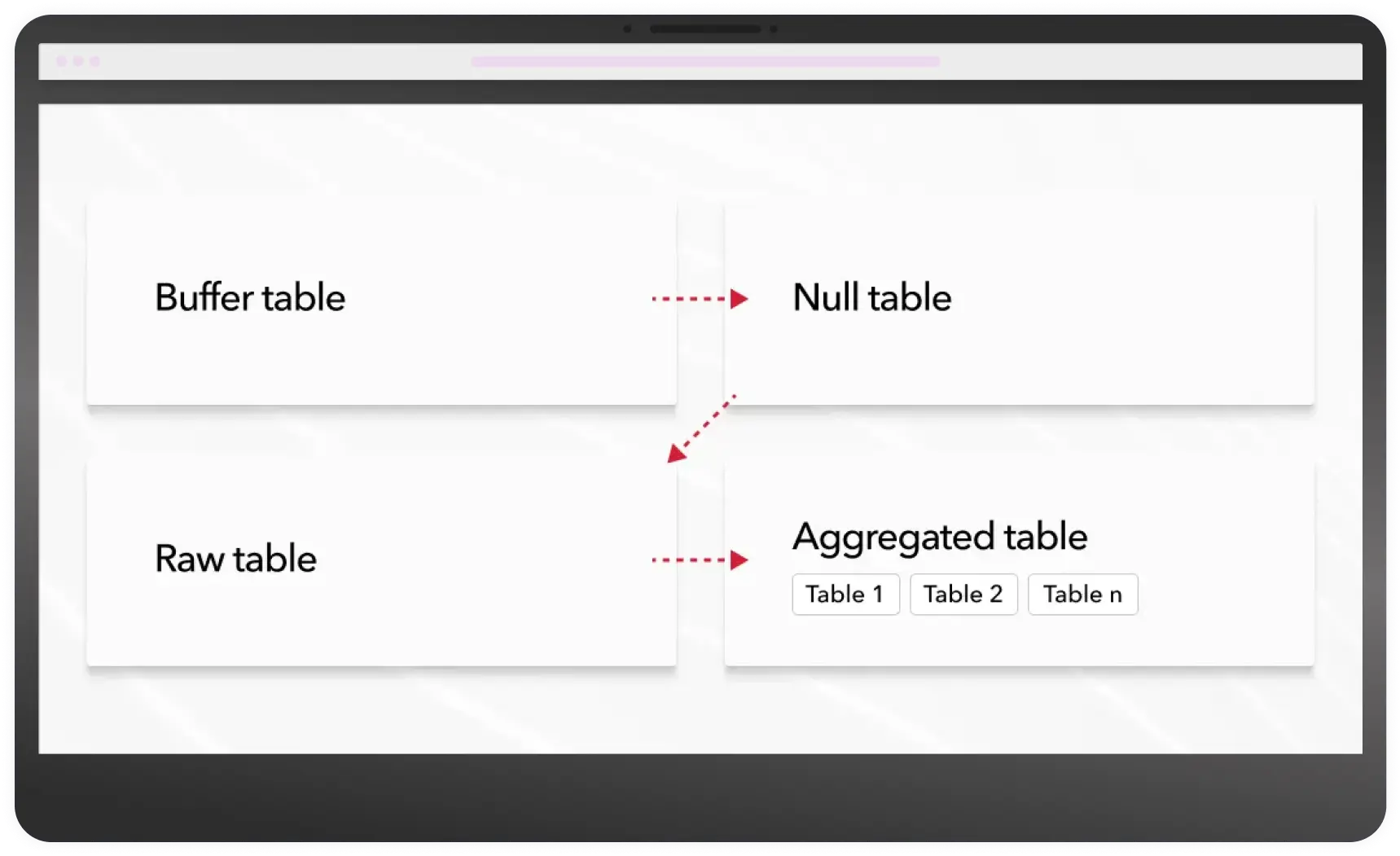
Accessing via the Application Layer
Data Copy penalty
Big Data always gives you a hard time when you transfer information from one place to another. Any storage type has the end resource and durability. Talking about SSD — the resource is pretty much limited. Most consumer-grade SSD has only 600 full disk write cycles. The enterprise-grade SSD (for data centers) has 1600 full disk write cycles.
For 100 Gbit per second network traffic, we need to write the following:
100 * 10^9 / 8 * 3600 * 24 = 1.08 * 10^15 (bytes) per day, which is around 1 Petabyte of writing every single day.
10 enterprise-grade SSDs with 4TB of storage each can handle only:
10 * 4 * 1600 = 64000 (TB) of data during their entire life.
For handling all traffic from only 100Gb over one year we need to write 365 PB of data, which is around
365000 / (4 * 1600) = 57 enterprise SSDs, 4 TB each.
“57 enterprise SSDs every single year!”
This is the reason why we do not use the queues services as intermediate.
Minimizing Data Storage
Driving Business Outcomes for the Client

Before: Data processing used up extra storage putting a big hurt on the client’s Capital Expenditures.
After: The client benefits from precise insights on ad serving locations and timings; resulting in millions of dollars saved annually from potential lost network connections or missed advertising opportunities. The Rust programming language and optimized algorithms provide us with opportunities to use fewer computing resources and save costs.

Before: Digging for data in analytics took from several minutes to over 1-hour time period. Other than slow data delivery, some data could be lost in the cracks.
After: The optimized data structure in the Columnar Database provides quick responses over billions of rows, reducing it from minutes (or hours) up to 300 milliseconds. Enhanced performance facilitates requests that are now being handled in near-real time.

Before: Their mobile traffic data volumes were increasing exponentially, resulting in timeouts and system overload.
After: Sharing of the Columnar Database provides opportunities for flexible scaling up and down. The whole analytics system is prepared to handle volatile data volumes proving to be resilient to any kind of scenario in the future.

Before: Their Data Center sometimes was unavailable from the remote locations, which resulted in significant data loss.
After: The proxy layer provides opportunities to define the healthiness endpoint of the Data Collection layer and temporarily save data for any disaster. The Data Collection layer is duplicated and distributed over a variety of computing instances.

Before: Their business experienced up to 600 incidents per year, caused by server overload or inaccurate data flow.
After: The Application layer provides access to the API with centralized authentication via LDAP (the whole system itself is behind the NAT), reducing the number of incidents from 600 to 50 incidents per year.
SUMMARY
The new developments turned out to be a game-changer for the client’s business. The cellular network provider has opened doors to new opportunities — from running targeted advertising campaigns to an all-around view of their customers and the clear foresight to mitigate any risks related to data security.
Ignoring the importance of real-time analytics in your cellular network business could lead to devastating data breaches and clear opportunities missing. If you’re serious about scaling your company, then you need to start implementing sustainable big-data analytics solutions.
said their newly appointed Chief Information Officer